

55·
4 days agothere are some real gems in this release, for example


there are some real gems in this release, for example
happy bday!
everybody needs to read In Praise of Idleness in my opinion https://files.libcom.org/files/Bertrand Russell - In Praise of Idleness.pdf
yeah the numbers are pretty useless if you don’t consider the cost of living
If we go by PPP, Russia is now the fourth largest, with Japan in 5th and Germany in 6th
https://www.worldometers.info/gdp/gdp-by-country/?source=imf&year=2025&metric=ppp®ion=worldwide
Absolutely, it’s a combination of anxiety about GenAI being seen as a threat to people’s jobs under capitalism coupled with the whole idea that humans have souls that cannot be replicated by material means. It’s pure idealism in my opinion.
Furthermore, I’d argue what is art is an inherently subjective question. When I see a painting, or hear a piece of music, or read poetry, what matters is what emotions it evokes within me. And that’s determined by my subjective experience, which shaped the topology of the neural connections within my brain. If I see something, and it triggers thoughts that are meaningful to me, then it’s art from my perspective.
How a particular piece of art was produced is entirely beside the point here. Most of the time when I see art, I have no insight into what the artist was thinking, what motivated them to produce a particular piece, or even what they were trying to convey with it. I project my own interpretation on the art and that’s how I decide whether it has value or not.
It’s been obvious that he’s not capable of doing serious material analysis ever since he started peddling the whole tech feudalism thing. It’s been a transparent attempt to sanitize capitalism by claiming that what we’re seeing is somehow a deviation from the way capitalism functions as opposed to just the natural progression of the system. Here we’re seeing more of the same, except now he’s mixing in some red scare as the mask finally drops.
basically the whole thing is made up, two great articles from a mainstream source
It’s such a great real world example of how LLMs are a practical tool in the class struggle. What would have been a Herculean, if not impossible, task for a small team is now achievable in automated fashion within a week. By automating the grunt work of translation and content creation, these tools allow us to break the cultural hegemony of the ruling class and rapidly build our own ideological infrastructure. We are now able to contest the bourgeois narrative on a scale that was previously simply not possible.
That’s exactly my thinking here as well. The usefulness of LLMs is now a material fact, and their widespread adoption makes the question of the future direction of this tech a matter of strategic importance. I’d also argue that this precisely is where we see the fundamental divergence between liberal and communist mindsets.
The liberal tendency often defaults to a form of procedural opposition such as voting against, boycotting, or attempting to regulate a problem out of existence without seizing the means to effect meaningful change. Their idealist mindset mistakes symbolic resistance for material change. Many anarchists fall into the exact same cognitive trap as well incidentally.
On the other hand, communists understand that real change is a product of our collective labor which is what praxis is. If we do not want the future of AI to be dictated by corporate interests, then the only effective response is to do the work ourselves. We must build our own tools that work the way we want them to. Chinese companies have already done a lot of leg work for us by publishing high quality open source models we can built upon. We don’t even have to start from scratch here.
hazelnut might be a strong competitor today :)
Oh yeah I agree, NATO is absolutely off the table and likely EU membership as well at this point given that EU is becoming more of a military alliance at this point. I also wouldn’t rule out total victory, once the AFU starts collapsing then there’s really not going to be any way to reverse that. At that point, Russia can dictate whatever terms it wants. I really can’t imagine Russia settling for any sort of a ceasefire, they’re going to finish this decisively.
I also don’t really see the EU being able to do much here. They can pump money into Ukraine, but they can’t solve the manpower problem or provide ammunition in volumes that would remotely make a difference. The US is needed to keep the war going, and even the US industry isn’t keeping up anymore now that the existing stocks have run down.
The collapse of the EU core states shouldn’t be ruled out either given how things are going in UK, Germany, and France right now. I actually wrote about this in some detail recently. https://dialecticaldispatches.substack.com/p/the-terminal-crisis-of-european-neoliberalism
The most interesting scenario, the implications of which I haven’t really seen discussed much, is that Russia absorbs everything aside from a rump western Ukraine where anti-Russian sentiment is the strongest. That would become Europe’s problem, and since it wouldn’t be a viable state economically, that would mean Europe having to dump billions into propping it up. If Europe allows it to collapse then there will be a refugee crisis compounding the current economic disaster.
From Russian perspective, Ukraine isn’t the root problem, it’s just a tool that NATO is using to fight them. So, their goal has to be to neutralize NATO as a threat. Putting stress on the economy in Europe seems like the logical way to go about it. We’re already seeing a huge political crisis unfolding with the neoliberal centre collapsing, and that’s creating political opportunities for Russia to exploit. I’m sure I thought of this, it must’ve been gamed by Russian planners as well.
I expect that’s very likely the plan. Once Zaporozhye falls, I expect Odessa will be next and from there there’s a straight path to Transnistria. Russia is likely planning to exhaust the AFU in the north first, and take Krasnoarmeysk (Pokrovsk) which will cut the logistics between the north and the south.
another good essay here as well https://www.artnews.com/art-in-america/features/you-dont-hate-ai-you-hate-capitalism-1234717804/
Also, a long dive into how a lot of the anti-AI hatred is funded by right wing corps that are unhappy that it’s infringing on their IP https://www.youtube.com/watch?v=lRq0pESKJgg
I mean Belarus and Russia form a union state now, so I don’t know if the distinction would be meaningful here.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
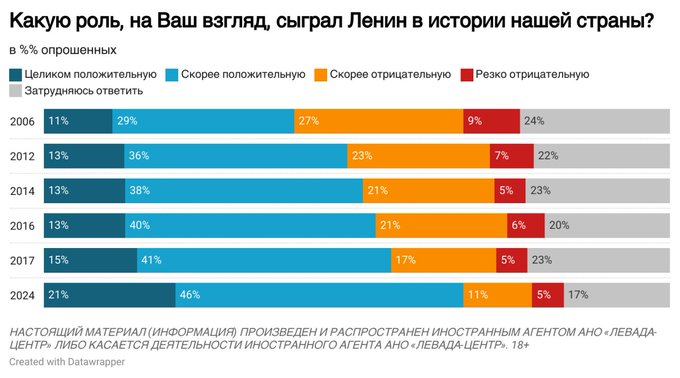{kind=link}
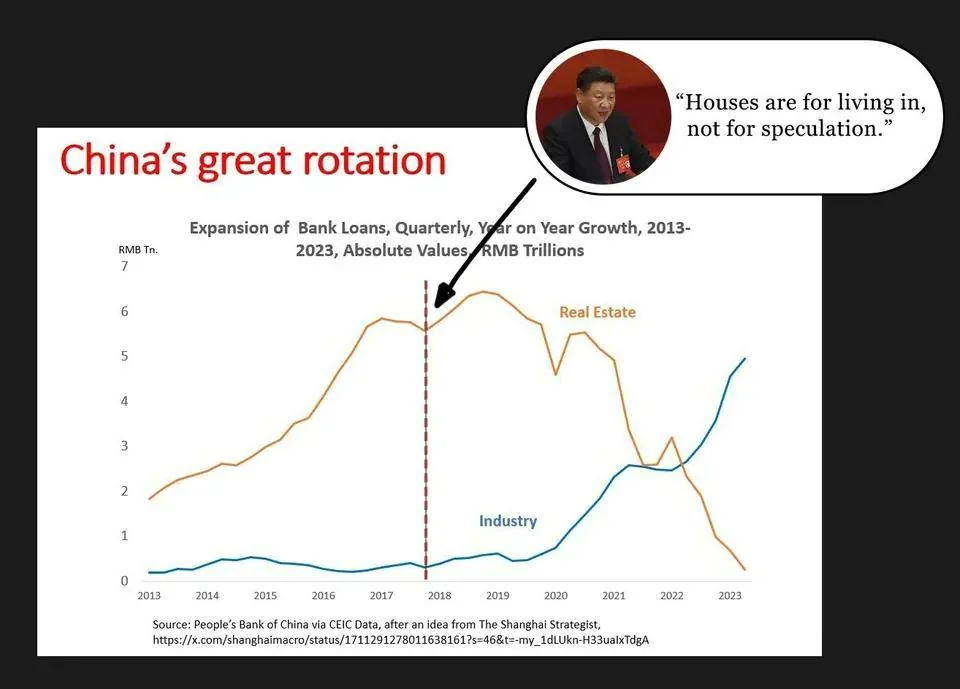{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
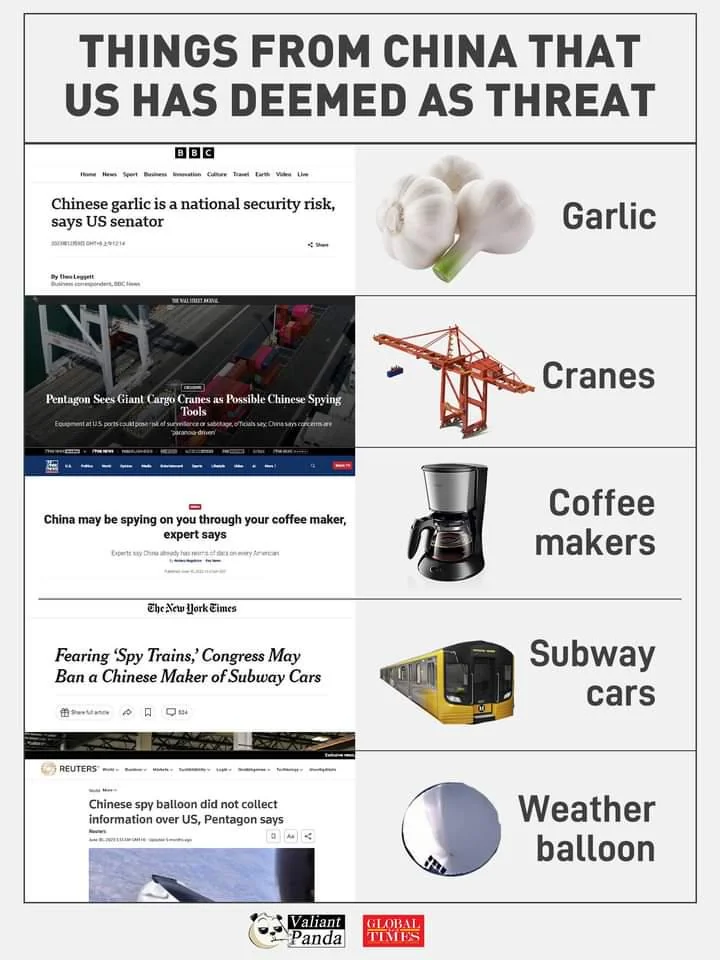{kind=link}
{kind=link}
I’m banned on world at this point, but feel free to post :)