
Thanks, bot. I did just wonder what linking to it with that syntax would do. :)
Ephera
- 10 Posts
- 457 Comments
Joined 4 years ago
Cake day: May 31st, 2020
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Oh hi, have you considered joining the best Lemmy community, !dcss@lemmy.ml? 🙃
If you’re into zombies and post-apocalyptic survival, CDDA always looks like a blast to play: https://cataclysmdda.org
Could you create the issue? I don’t use GitHub and I just won’t spend half an hour to create a throwaway mailbox + account, to paste some text into the appropriate place.
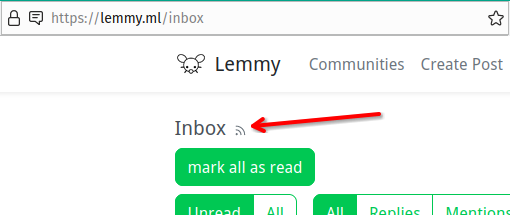
Here’s the issue text, as I would formulate it, and a screenshot, if you want it:
Account Inbox RSS-Feed has broken URLs
The feed reachable via the RSS-button in the account inbox has been broken for a couple weeks.
It uses URLs like this: https://lemmy.ml/post/971001/comment/442247
Which, if loaded in a browser, gives an error:
404: TypeError: Cannot read properties of undefined (reading 'send').If the section “post/971001/” is removed from the URL, it loads the intended comment: https://lemmy.ml/comment/442247
Steps to reproduce:
- Log into your account.
- Go to
<Lemmy-instance-URL>/inbox, e.g.: https://lemmy.ml/inbox - Click on RSS-button.
- Open the downloaded file in a text editor. You should be able to spot the wrong URLs in the XML.
This issue was reported by https://lemmy.ml/u/Ephera .


 11·1 year ago
11·1 year agoWow, I figured, Reddit simply didn’t want 3rd-party apps anymore and for PR reasons decided to name a high pricetag rather than discontinuing the API altogether. But they’re going way beyond that, trying to shame individual app developers etc., which is really not helping their PR.
If you’re into chocolate milk, I’ve found pre-mixed chocolate oat milk to have a really nice mouthfeel (IMHO better than cow milk). Obviously, your mileage might vary, though, depending on the brand…
It’s generally assumed that oat milk will easily become cheaper than cow milk when mass production takes off. It requires fewer resources (no cows consuming energy) and the process is easy to automate.
But yeah, for now, lactose-intolerant and vegan folks need to pay high prices to kickstart that…
That surprises me, since I’m told (a large part of) India deems cows holy and over here, the cheapest milk is from cows kept under inhumane conditions…
Well, cool that it works for you, but that is kind of why I stay away from the GUIs, too: I do not want to forget how the CLI works. Or even just become less comfortable in it.
When you need to look anything up about Git, you get told commands, and I need to mess with Git repos on remote servers every now and then.
Also, even if I can’t help colleagues in their GUI, they generally have the CLI somewhere.I do use a shell with type-ahead suggestions to alleviate the typing somewhat.
Yeah, I always tell new trainees, they can use a GUI, but they won’t get around learning how the CLI works, as when they look anything up about Git, they’ll only find commands.
That’s me with Git. If my colleagues need help and they’re on the CLI, I can just literally spell them out everything they need. But if they’re using some sort of Git GUI, it’s always like, WTF are all these buttons? Are you sure, Git even has that many features? How do I tell it to do XYZ with certain flags? Are you sure, this isn’t missing some Git features?
By the way, the feed reachable via the RSS button in the account inbox has been broken for me, for a couple weeks. Probably should’ve reported that earlier…
It uses URLs like this: https://lemmy.ml/post/971001/comment/442247
Which, if I load it in my browser gives me an error
404: TypeError: Cannot read properties of undefined (reading 'send').If I simply remove the “post/971001/”, it loads the intended comment: https://lemmy.ml/comment/442247
There’s no setting, as far as I’m aware.
You can use a browser extension to tweak webpage styles, like for example Stylus.
And then add a rule like this:.container, .container-lg, .container-md, .container-sm, .container-xl { max-width: 1337px; }Tweak the
1337to however wide you like it.But absolutely no guarantee that this rule will continue working, if the Lemmy devs do any updates to the UI, nor that it doesn’t lead to visual glitches now or in the future.
I mean, that probably sounds scarier than it really is. I’m rather saying, appreciate that a hack like this is possible, don’t take it for granted.
 7·1 year ago
7·1 year agoYeah, I’m often thankful to people building these frontends, because ultimately a lot of human information is in those corporate silos and accessing them via a frontend is better than directly.
But at the same time, I would never build such a frontend myself, for the reason you mentioned.
All it takes, is a bunch of profiteering dickwad investors, to make your efforts go poof.
If you’re viewing this post from the Lemmy webpage (lemmygrad.ml, in your case), you can click on the rainbow-colored Fediverse icon to see how it looks like from their end.
You can try finding people via hashtags…
Expressing that a politician is bad at their job is not hate speech. That is an opinion and very much protected by free speech.
Hate speech is a very specific term: https://en.wikipedia.org/wiki/Hate_speech
I introduced the term into this discussion, because I assumed, the commenter above me meant that.

Well, I don’t consider hate speech to be an opinion. In the USA, in my country and presumably most countries, hate speech is a crime in itself.
They did not say that there’s no relation to politics at all. But we do not need to hold a particular political position to agree that the government should not censor people’s opinions.
It only starts to become a right-wing talking point when liberally applied to everything else. When even government officials argue your opinion should be censored, because it is critical of their opinion. That has nothing to do with the actual free speech principle. Quite the contrary.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
Problem is, you don’t always get error codes. An error code is only useful, if you can output it to somewhere, so lots of machine manufacturers or programmers save themselves the trouble.
And error codes are an incredibly limiting interface. You can’t provide dynamic information with them. Or, programmers may choose to include an error into another error code, because it’s “close enough” for them to not want to update the manual.
Meanwhile, text logs get all the detailed information you actually need for debugging, with the downside of being an entirely unstable interface.
I’m not happy about this state of the industry either. I’m just saying, many companies will gladly take 95% accuracy over having to upgrade their machines or investing time to ingest the various signals.