
☆ Yσɠƚԋσʂ ☆
- 4.44K Posts
- 4.62K Comments











 2·2 days ago
2·2 days agoRight, but all the infrastructure supporting international medical services was developed at cost through massive state investment. Now that it exists, using it is cheap, so you can charge low prices to foreigners for access and still make a profit.





you are literally sniffing so much glue that your mind exists on another plane of existence
I would argue that it is in fact bad because it’s a threat to national security and sovereignty. The Europeans are now finding out that they’re unable to produce things domestically that their people need, and have become entirely reliant on US energy exports and military protection.
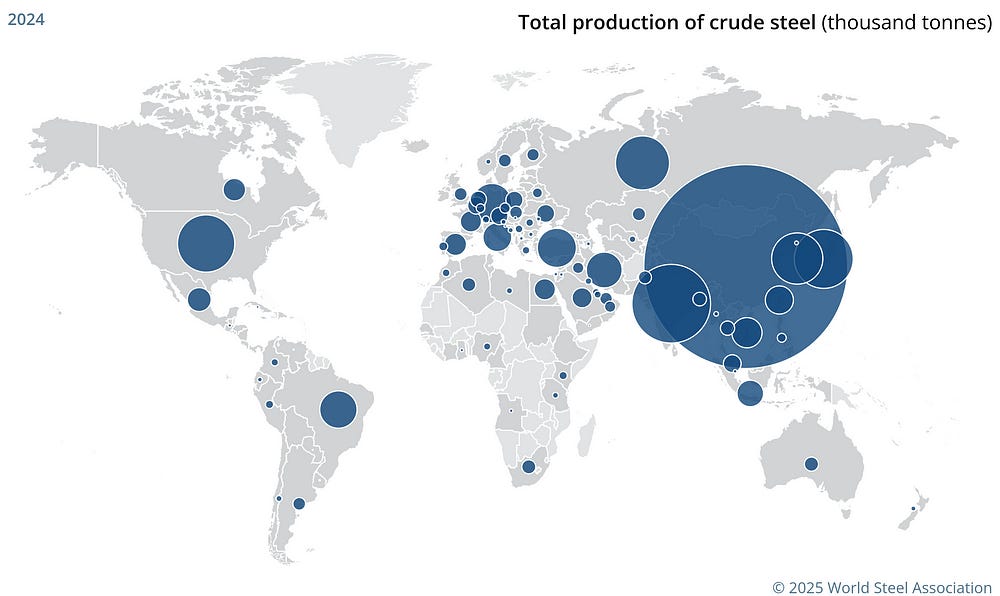
China isn’t forcing anybody to buy their goods at gunpoint last I checked. The fact that western markets are unable to produce comparable goods at the same prices is entirely the problem with the way western economies are structured. The whole premise for loosely regulated markets was that they were supposed to be more efficient than state planning, turns out that was a big fat lie. So now the dumb fucks in the west are crying that their failed economic model can’t compete with China. Tough!
It’s pretty clear that Epstein network operated all throughout Europe. Mandelson revelations being a prime example of this.
medical in China is so insanely cheap precisely because it’s not run for profit
Also, it’s fascinating how agency and self determination is only reserved for movements that are pro western. Notice how easily liberals dismiss the right of LPR/DPR for self determination.


British media, in particular, has been making some hilariously hamfisted attempts to draw a connection
- https://news.sky.com/story/i-still-would-like-to-meet-putin-epsteins-unrequited-love-for-russian-leader-13502862
- https://www.thetimes.com/world/europe/article/jeffrey-epstein-investigated-for-being-a-russian-spy-tpcplhvxp
- https://www.france24.com/en/tv-shows/press-review/20260202-daily-mail-epstein-s-sex-empire-was-honeytrap-directed-by-the-kgb

meanwhile in the real world
typical Chinese adult is now richer than the typical European adult https://www.businessinsider.com/typical-chinese-adult-now-richer-than-europeans-wealth-report-finds-2022-9
90% of families in the country own their home giving China one of the highest home ownership rates in the world. What’s more is that 80% of these homes are owned outright, without mortgages or any other leans. https://www.forbes.com/sites/wadeshepard/2016/03/30/how-people-in-china-afford-their-outrageously-expensive-homes
Chinese household savings hit another record high in 2024 https://www.wsj.com/livecoverage/stock-market-today-dow-jones-bank-earnings-01-12-2024/card/chinese-household-savings-hit-another-record-high-xqyky00IsIe357rtJb4j
The real (inflation-adjusted) incomes of the poorest half of the Chinese population increased by more than four hundred percent from 1978 to 2015, while real incomes of the poorest half of the US population actually declined during the same time period. https://www.nber.org/system/files/working_papers/w23119/w23119.pdf
From 1978 to 2000, the number of people in China living on under $1/day fell by 300 million, reversing a global trend of rising poverty that had lasted half a century (i.e. if China were excluded, the world’s total poverty population would have risen) https://www.semanticscholar.org/paper/China’s-Economic-Growth-and-Poverty-Reduction-Angang-Linlin/c883fc7496aa1b920b05dc2546b880f54b9c77a4
Real wage (i.e. the wage adjusted for the prices you pay) has gone up 4x in the past 25 years, more than any other country. This is staggering considering it’s the most populous country on the planet. https://www.youtube.com/watch?v=Cw8SvK0E5dI
Over the past 40 years, the number of people in China with incomes below $1.90 per day – the International Poverty Line as defined by the World Bank to track global extreme poverty– has fallen by close to 800 million. With this, China has contributed close to three-quarters of the global reduction in the number of people living in extreme poverty. https://www.worldbank.org/en/news/press-release/2022/04/01/lifting-800-million-people-out-of-poverty-new-report-looks-at-lessons-from-china-s-experience
None of these things would be happening in China if it was doing capitalism. It would look the way other capitalist shitholes look like today.
Gotta love guzzling CIA propaganda uncritically.
Imagine being over the age of 10 and using the word authoritarianism like it means anything.
 4·5 days ago
4·5 days agoI’d expect they will be Linux friendly just because there’s a big push towards using Linux in China now since they want to decouple from western proprietary tech. I guess we’ll have to wait to see once they become generally available though.
Plenty of anarchists have the exact same position as the US regime when it comes to western adversaries like China.
UN can absolutely impose sanctions, the actual problem is that the west is a bunch of rogue states that take unilateral action ignoring the UN.


{kind=link}
{kind=link}
The simple answer is it’s because western liberal regimes are not democracies. A system where you have one set of laws for regular people, and another for the affluent is a plutocracy.